The history of the web browser
Blog post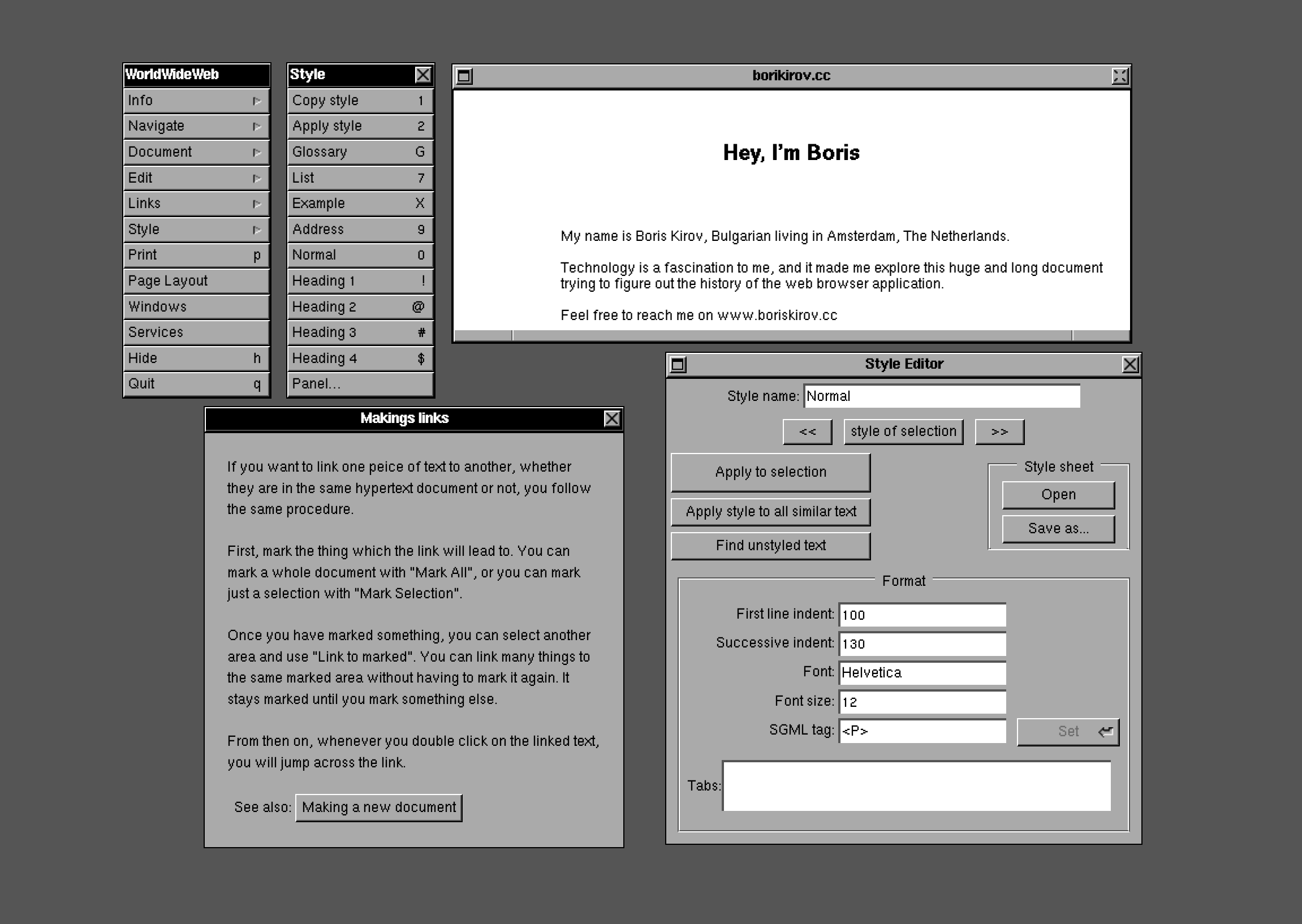
To understand our surroundings, we need to start digging through history. History always provides us with better insights into how and what we can expect from the future. We understand the reasons why certain things were designed the way they are, and we can also predict with a certain level of confidence the next version of it. We can also understand the connectivity between the past, present, and future.
For us to be sequential in our innovation, we need to connect the dots of the past and be thankful for the people that created our amazing present. The saying from Sir Isaac Newton feels so relevant here "If I have seen further, it is by standing on the shoulders of giants". The giants are those same people that build the past to allow for the present to be here.
What we know is that "necessity is the mother of invention" which means that innovation, evolution, or upgrades in any essence of life come because of the primary driving force of the need. We move forward because of them. If you think even deeper about it, you will easily see the relationship between some of the human inventions: the wheel, chariot, steam engine, train, bicycle, automobile, airplane. You can see how those inventions are connected and because you are so familiar with them you can easily understand the sequence of them and the reasons why.
When we think about the internet when we think about the web browsers we need to clearly understand that many things were done back in those days, by many people. The foremost gratitude should go to Sir Timothy John Berners-Lee for creating a path that generated a momentum of events that today feel so relevant are normal. But before asking ourselves about the first web browser, we need to understand where this need came from. The need for the web browser.
The race for science
The end of WWII was a historical moment for the human race, which generated a wave of scientific interest in nuclear energy. But because of Europe's sufferings, the US was leading the parade in the energy research game. In July 1945, one of the most famous American engineers and inventors Vannevar Bush who was also the leading director during the WWII of the U.S. Office of Scientific Research and Development (OSRD) wrote a paper for the Atlantic Monthly and shared:

“Consider a future device … in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility. It is an enlarged intimate supplement to his memory.” - the concept of hypertext had been invented.
The future was now and Europe was falling behind, so that led to a decision by the EU states in 1952 to create the "Conseil Européen pour la Recherche Nucléaire" (CERN) near Geneva, Switzerland. And in the next 30 years, CERN was accelerating different initiatives in the realm of energy & nuclear power. CERN became a huge international organization with large teams developing complex apparatus spread across several continents.
But it was not only CERN, many organizations around the world were generating content that needed to be stored, maintained, and reached. They were using computer machines with simple text editing applications. In 1967 William Warren Tunnicliffe gave a presentation in front of the Canadian Government Printing Office, on the separation of the information content of documents from their format. The need for a markup language was born. Then Tunnicliffe led the development of a standard called GenCode for the publishing industry.
The markup language that we know now has a concept and an idea behind it. It evolved from the terminology of "marking up" of paper manuscripts. It was a form of communication for editors to identify and mark content corrections (such as spelling, punctuation, or movement of content), and also typographic instructions, such as to make a heading larger or boldface. It was most common to use a blue pencil to present those changes. In today's world, our blue pencil marks are substituted by tags (often seen in blue).
By 1969 one of the research teams of IBM led by Charles Goldfarb, Ed Mosher, and Ray Lorie developed the first markup language, called Generalized Markup Language, or GML. Using GML, a document is marked up with tags that define what the text is, in terms of paragraphs, headers, lists, tables, and so forth.
:body.
:h1. Hello, I'm Boris
:p. Bulgarian Product designer, currently
living in Amsterdam, The Netherlands
>:ul. My interests are:li. Technology
:li. Sofware
:li.Design
:li. Systems
:eul.
:p. Nice to meet you`
This was the first time when tagging of elements was hierarchical and would allow you to start and end a certain type of text. GML used the symbols colon ":" and fullstop "." as tag delimiters but used h1 to define major headings, p for paragraph, ol for an order list, and li for a list element. For those with a knowledge of HTML, these should be quite familiar. However, end tags did not use the ":/ol." notation for the end tag but had ":eol.". GML had demonstrated that it was possible to markup information in a generic way so that it could be used by more than one application.
The need for a shared library
Organizations were now growing and the main goal was to ensure that everybody in the team is up-to-date with the information, especially when we talk about energy, nuclear power, and research. This distributed way of working and developing combined with the complexity of the topic meant that hundreds of computers networked together. They needed to be connected and communicate with each other, so experiments can be done faster, more efficiently, and with more control in order to collect data. The need for an application that could store and allow accessing this data was born. The need for a browser was here.
The year now is 1980, and more than 10,000 people are working in CERN on different programs both software and hardware. Information back then was shared through email and file exchange. Scientists needed a more scalable and easier to maintain a way of the information that has been generated and shared across the organization, a place where it can be stored and updated. That's when the English computer scientist Tim Berners-Lee started working on an application that was supposed to be compatible with:
- different networks
- different formats
- different encoding schemes
There was no application at this point in time to be that flexible, and easy to read so many different structures and data. The concept behind the connected browsing application was knocking on the door. But before it, the ENQUIRE program was designed.
ENQUIRE was a method for documenting, conceptually it was a simple hypertext application that allowed interrelation between different composable parts. This hypertext program solved the problem needs of storing, updating, and using information from creator to receiver. But sure it has its own limitations and flaws.
In Enquire, I could type in a page of information about a person, a device, or a program. Each page was a node in the program, a little like an index card. The only way to create a new node was to make a link from an old node. The links from and to a node would show up as a numbered list at the bottom of each page, much like the list of references at the end of an academic paper. The only way of finding information was by browsing from the start page.
— Tim Berners-Lee
The main advantage of ENQUIRE from the competitors back then like Apple's HyperCard was the portability and flexibility to run on different systems. It was built to answer the needs of CERN. But ENQUIRE wasn't the only unique hypertext application used in CERN, the European organization was running few applications for storing, sharing, and updating data: CERNDOC, VAX/VMS Notes and the USENET.
 Introduction of ENQUIRE Manual
Introduction of ENQUIRE Manual
The story behind ENQUIRE is more appealing not only because it is the first child of Sir Timothy but because everything about it has that unique creative touch. The name came from a Victorian book called Enquire Within Upon Everything. The book sold more than 1,428,000 copies and had the intention of providing encyclopedic information on topics as diverse as etiquette, parlour games, cake recipes, laundry tips, holiday preparation, and first aid. Literally everything.
 "Enquire Within Upon Everything" is a book of how to do things in domestic life It was first published in 1856 by Houlston and Sons of Paternoster Square in London.
"Enquire Within Upon Everything" is a book of how to do things in domestic life It was first published in 1856 by Houlston and Sons of Paternoster Square in London.
Something was missing
The hypertext application were running all around, but something was wrong and Tim had to go back to CERN for his second period and invest his time in solving the problems. There were more than one operating hypertext application and each of those required to be in one single machine. There was no way for the information to be shared outside of the system it was hosted on. On his second period at CERN Tim thought about reimplementing ENQUIRE but wanted to get away from the major constraint it had which was that all the files had to be on one machine.
“In those days, there was different information on different computers, but you had to log on to different computers to get at it. Also, sometimes you had to learn a different program on each computer. Often it was just easier to go and ask people when they were having coffee…”
— Tim said.
The reimplementation of ENQUIRE was needed. So there was a second trial to solve the information sharing need with few requirements:
- allow the system to work on more machines simultaneously
- be compatible with all data coming from ENQUIRE, the CERNDOC, VAX/VMS Notes and the USENET
In November 1990 Tim provided a proposal stating that he needs 5 people working on this for 6 months. Tim and Robert could work on the project plus Nicola Pellow who would write the simple browser that would run on any machine, the line-mode browser. The first web browser was born the WWW. WorldWide Web.
This new browser WWW was running on HTML. HTML was based on the SGML (Standard Generalized Mark-up Language) which was used in CERN. SGML was an internationally accepted method of marking up text. HTML parser ignored tags and attributes that it did not understand. As a result, all documents which were based on SGML were easily converted into HTML files with simple file renaming. The SGML elements used in Tim's HTML included p(paragraph); h1 through h6 (heading level 1 through heading level 6); ol (ordered lists); ul (unordered lists); li (list items) and various others. What SGML did not include were hypertext links. The concept of using an anchor element with the HREF (HTML Reference) attribute was purely Tim's invention, as was the now-famous www.name.name format for addressing machines on the Web.
The WWW was catching some attention and Joseph Hardin and Dave Thompson, both from the National Center for Supercomputer Applications part of University of Illinois were able to connect to the computer at CERN and download copies of two Web browsers. The importance of that discovery was undisputed and the browser Mosaic was born.
 Mosaic was the first browser to display inline images, and not in a new separate window.
Mosaic was the first browser to display inline images, and not in a new separate window.
Mosaic then generated a chain of events by dozens of inspiring and amazing people that created so many version and variations of the browsing experience. Things like CSS and JS were complete innovation that was born from the rise of the web experience.
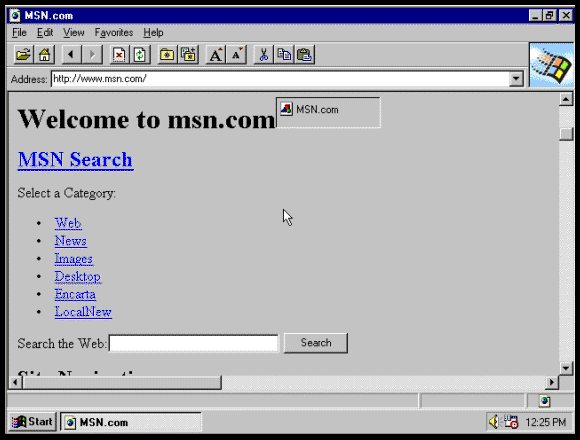 Internet Explorer 1
Internet Explorer 1
Netscape created and released JavaScript, which gave websites powerful computing capabilities they never had before. (They also made the infamous <blink>tag.) Microsoft countered with Cascading Style Sheets (CSS), which became the standard for web page design.
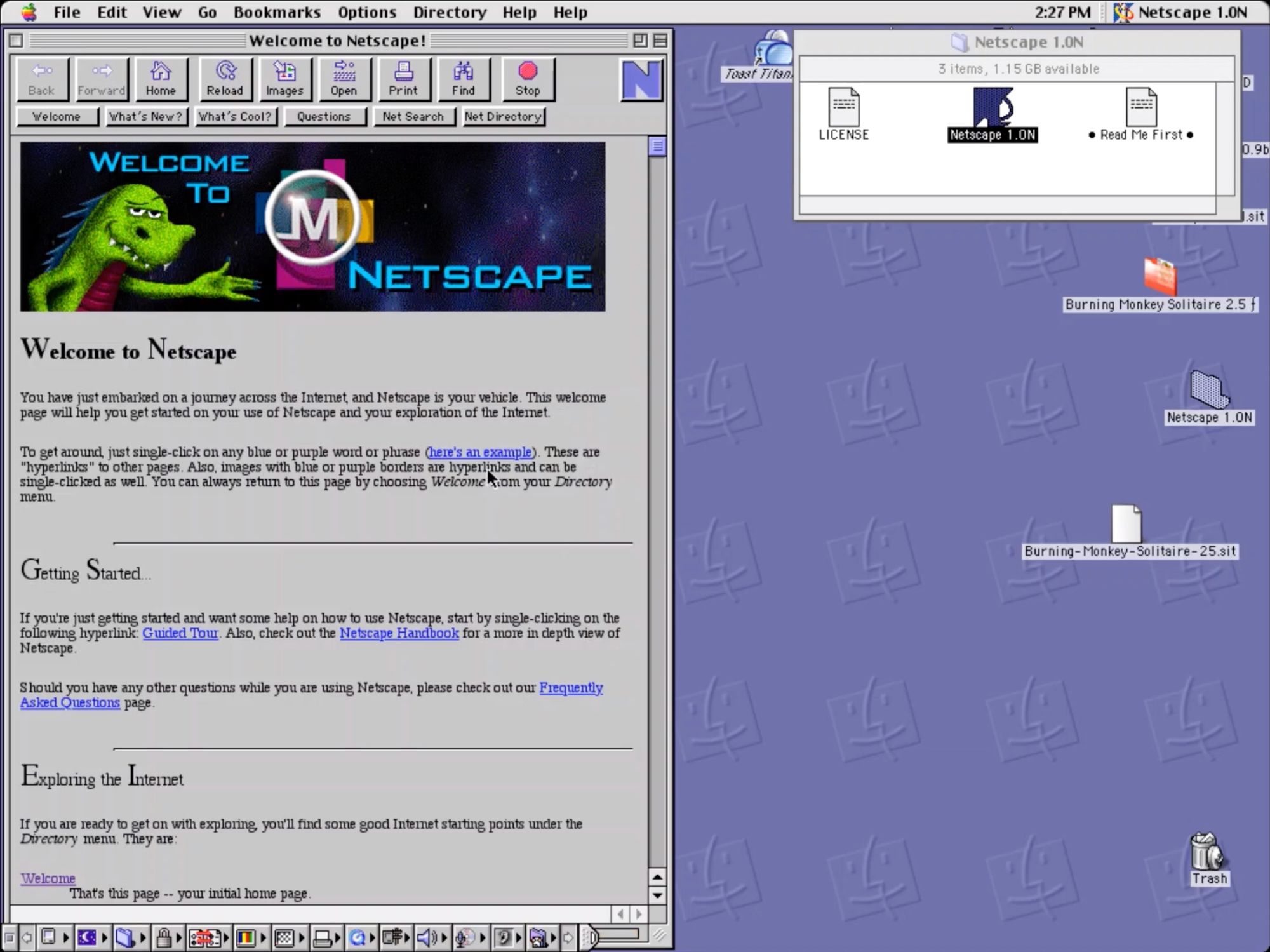 During development, the Netscape Navigator browser was known by the code name Mozilla, which became the name of a Godzilla-like cartoon dragon mascot used prominently on the company's web site.
During development, the Netscape Navigator browser was known by the code name Mozilla, which became the name of a Godzilla-like cartoon dragon mascot used prominently on the company's web site.
We can talk so much more about the web browser application, about Mosaic, Netscape, Viola, Internet Explorer, Mozilla Firefox (Netscape 🤫), Amaya, Safari, Opera, SeaMonkey or Google Chrome but the idea behind this long wiki looking post was to introduce the history behind everything that sparked the browser era that we live in.
Thank you giants for doing all the hard work!